Lectura en R
Lectura de datos en R
La mejor manera de tabajar con datos es realizando una lectura de una base de datos externa para procesar.
A continuación se indicarán los pasos y las recomendaciones para realizar este procedimiento.
Ubicación de los archivos que tienen la base de datos.
El primer paso es ubicar el lugar en donde se encuentra la base de datos que se quiera procesar.
En particular se prefiere que sea una carpeta nueva para impedir que se se confunda con bases de datos y guiones diferentes.
En la imagen se muestra los archivos de tiemposReaccion.xlsx y tiemposReaccion.csv.
Recuerden que en este
enlace
se encuentra el procedimiento para convertir un archivo de tipo
.xlsx a uno de tipo .csv.
En la misma dirección, bajo el título de Descargar trabajo completo, como archivo comprimido, se muestran algunos otros aspectos que hay que tener en cuenta cuando se hace este tipo de conversión y procedimiento.
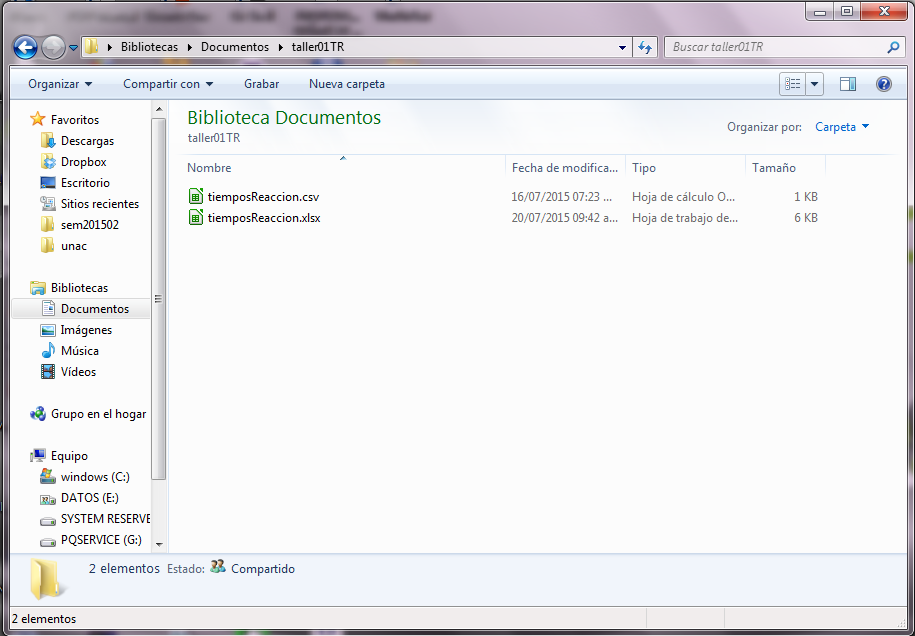
Ubicación del guión en el lugar de las bases de datos.
Este procedimiento es extremadamente importante a tener en cuenta para que el procedimiento sea exitoso.
Al grabar el guión (en este caso en el nombre de guion01TR, se debe grabar en el mismo lugar en donde se encuentran las bases de datos.
Así como lo indican la dos siguientes imágenes.
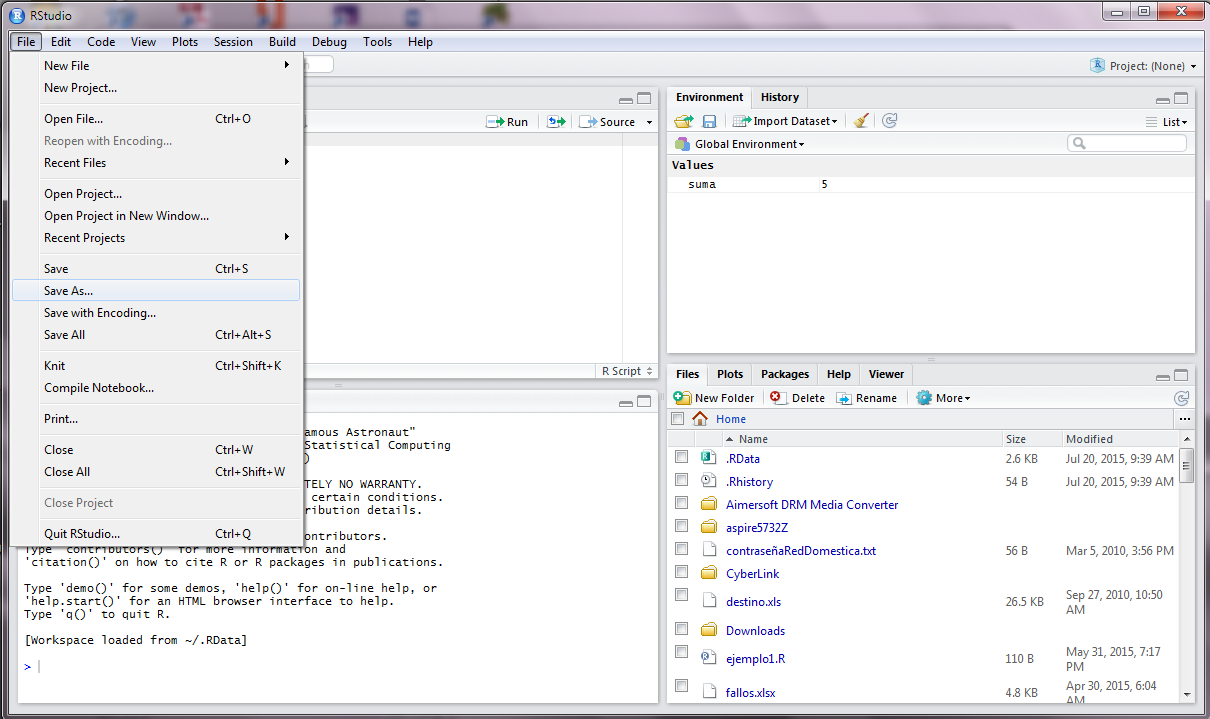
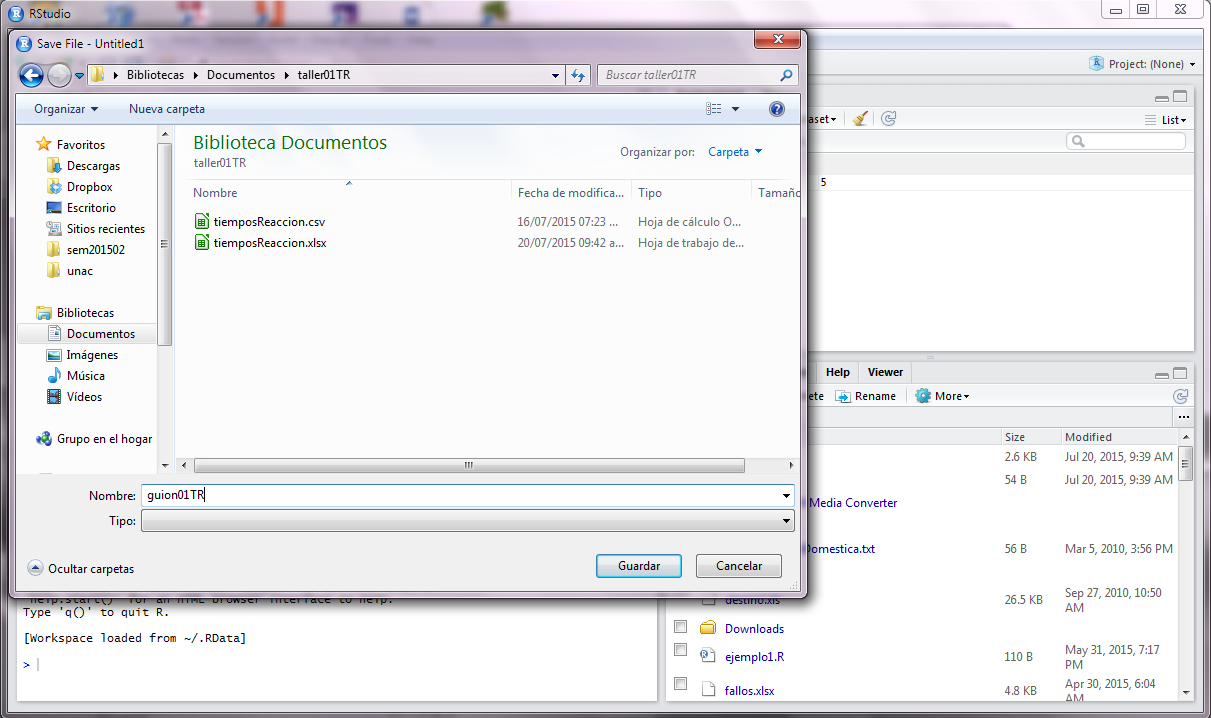
Verificación para saber si el RStudio está bien direccionado.
Una vez que se haya grabado el guión en el lugar en donde se encuentra las bases de datos, se procede a verificar si los archivos está disponibles para su lectura.
En la ventana de consola se escribe dir(), así como se muestra en la siguiente imagen.
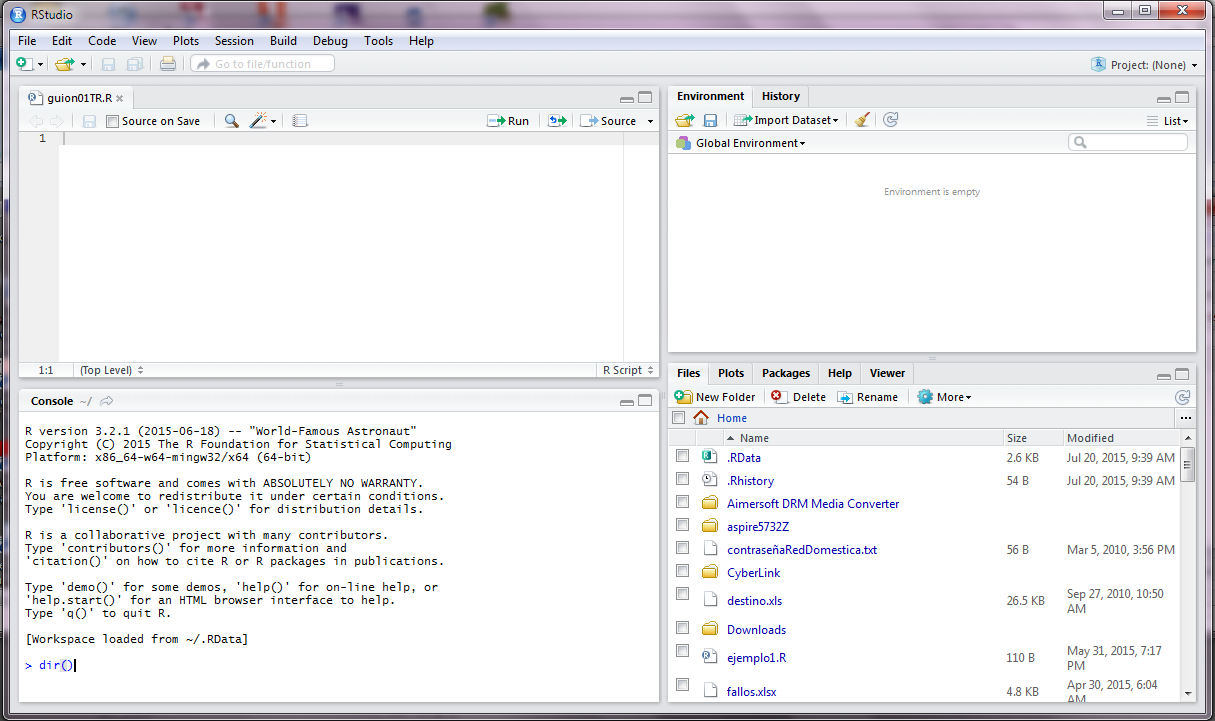
Si el resultado que se muestra en la pantalla de la consola no tiene los nombres de los archivos de las bases de datos, quiere decir que el RStudio no está correctamente direccionado. La siguiente imagen muestra que los nombres de los archivos de las bases de datos no se muestran en la pantalla de la consola.
Ubicación del RStudio en la dirección en donde se grabó el guión.
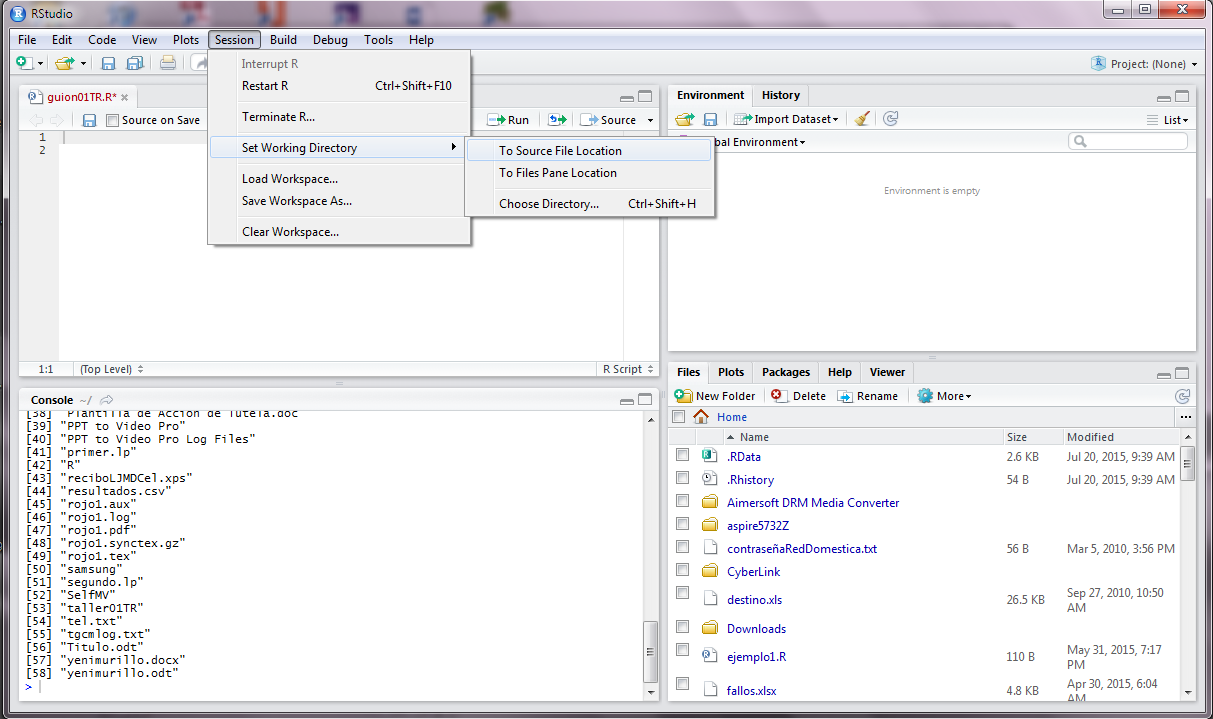
Para que el RStudio se ubique correctamente se procede a realizar el siguiente comando:
Session > Set Working Directory > To Source File Location.
Así como se muestra en la siguiente imagen.
Nuevamente verificación de la ubicación del RStudio.
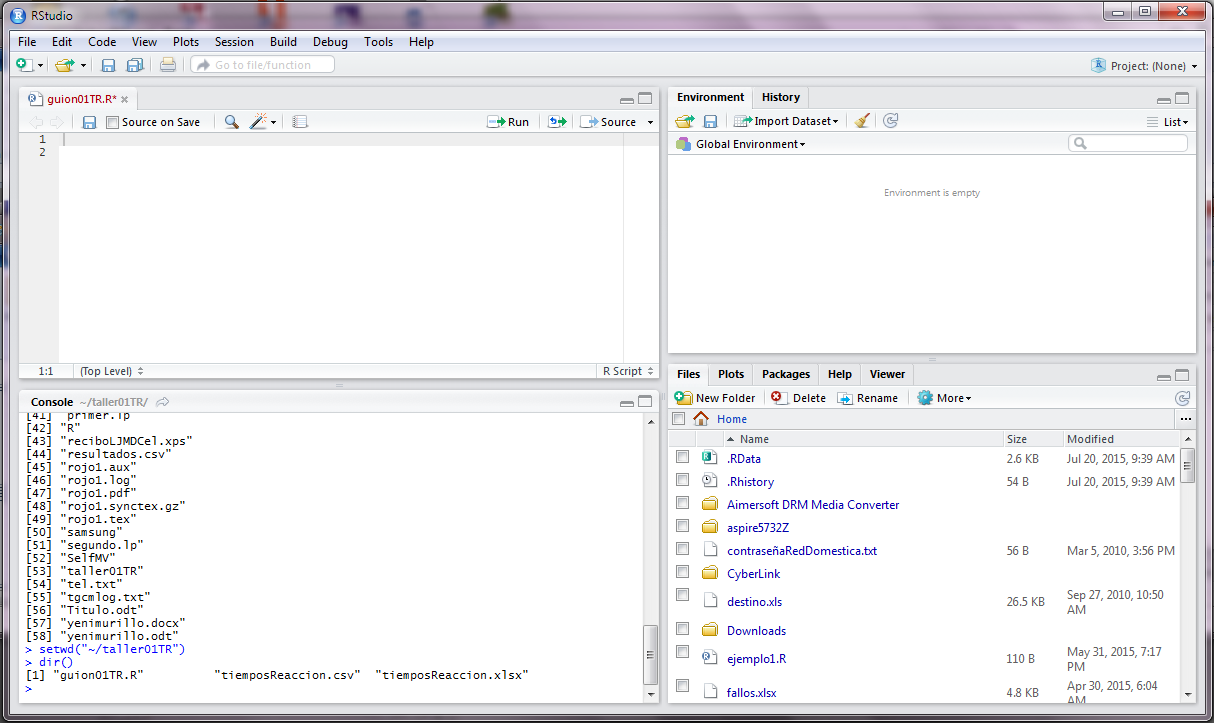
De nuevo en la consola se escribe el comando dir() y se verifica si ahora los archivos de las bases de datos están disponibles, como se muestran en las dos siguiente dos imágenes:
En esta imagen se muestra que aparcen los nombres de las bases de datos.
Lectura de la base de datos en RStudio.
El siguiente código corresponde al necesario para realizar la lectura de una base de datos en el entorno del R.
# Lectura de los tiempos de reacción.
TR <- read.csv2("tiemposReaccion.csv")
Es guión se guardó con el nombre de guion01TR.
Resultado de la ejecución del código de lectura de la base de datos.
Cuando se ejecuta el comando de lectura en el entorno aparece el nombre de TR, que es el nombre que se utilizó dentro del R para denominar la base de datos.
Al código se le puede añadir la línea para mostrar la base de datos, asi:
# Lectura de los tiempos de reacción.
TR <- read.csv2("tiemposReaccion.csv")
TR
Si se hace un click en el ícono del lado izquierdo del nombre TR en el entorno se muestran las variables y los tipos de cada variable.
Mostrar el contenido de la base de datos en la consola.
Al ejecutar el código se muestra el resultado en la consola de los datos de la base de datos como se muestra en la siguiente imagen.
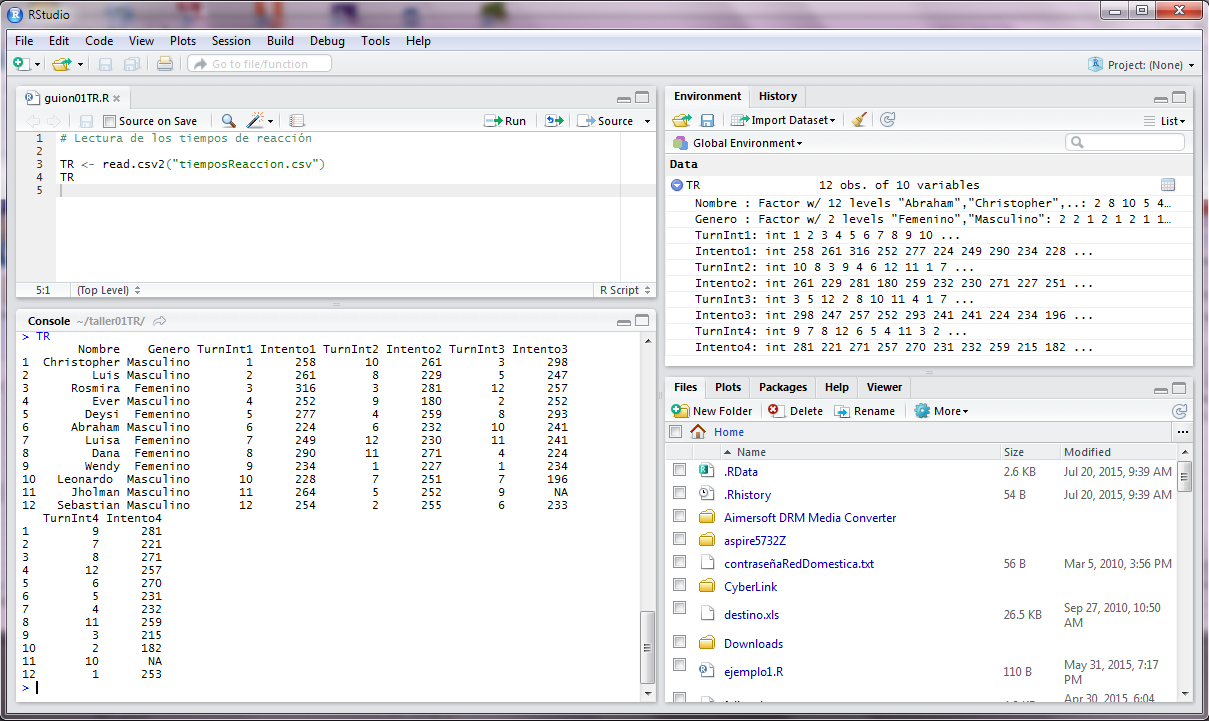
Trabajo con la base de datos.
El código se le añaden líneas para que quede ahora de la siguiente manera:
# Lectura de los tiempos de reacción.
TR <- read.csv2("tiemposReaccion.csv")
TR
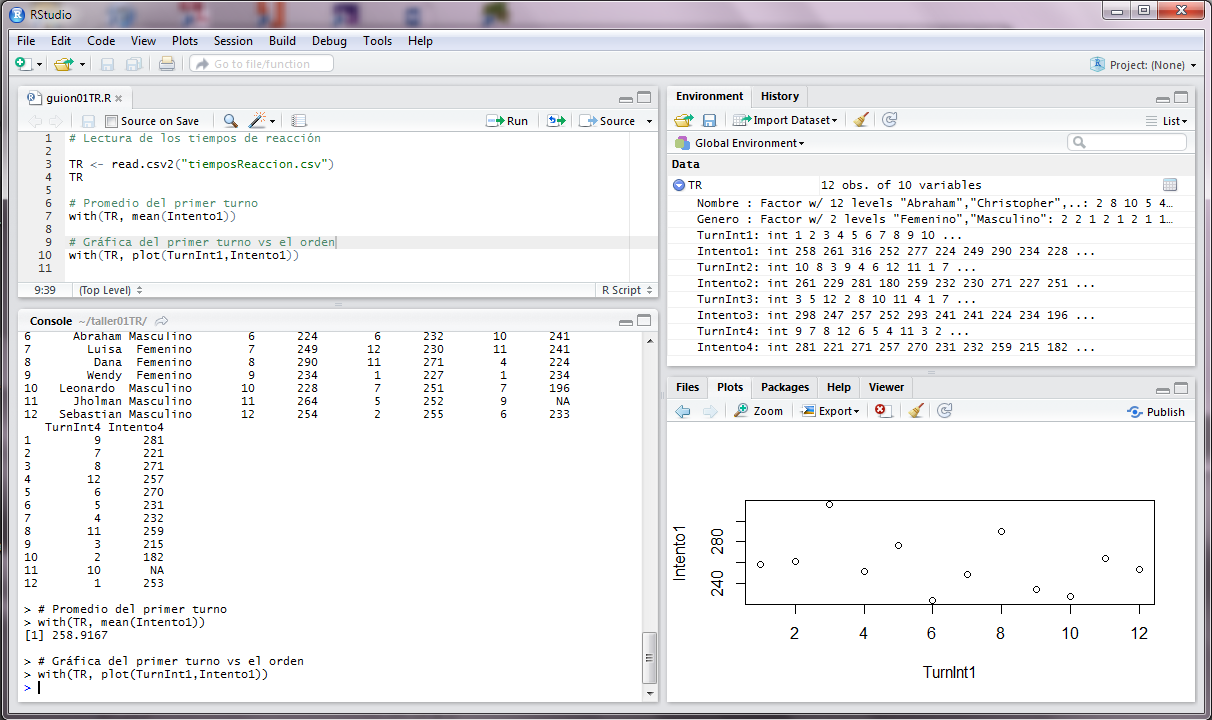
# Promedio del primer turno
with(TR, mean(Intento1))
# Gráfica del primer turno vs el orden.
with(TR, plot(TurnInt1, Intento1))
El resultado de la ejecución se muestra en la siguiente imagen.
Guardar el espacio de trabajo.
Si se quiere terminar con el trabajo al salir se pregunta si se quiere grabar el espacio de trabajo. Es recomendable hacerlo para conservar el trabajo realizado en el entorno.
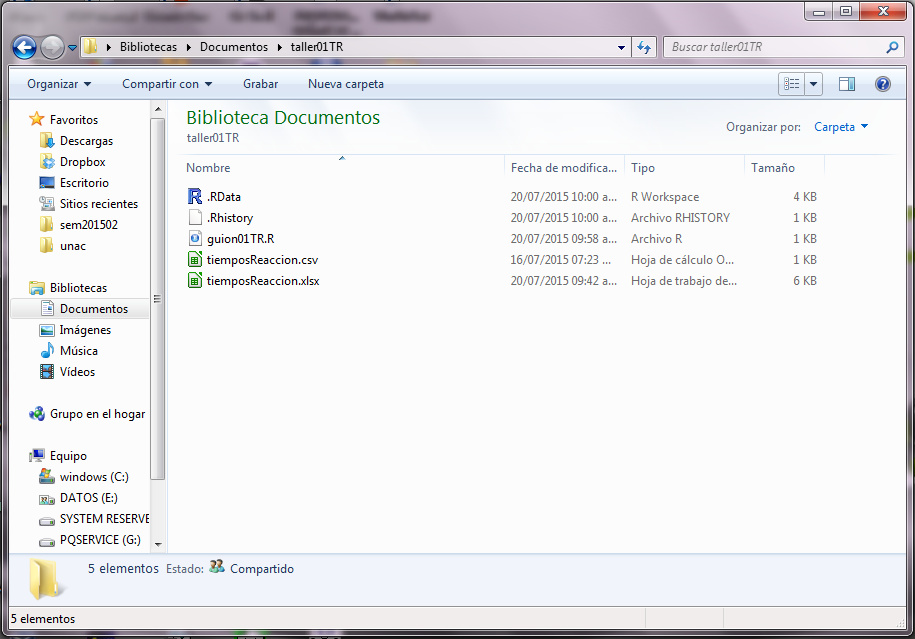
Aspecto final de la carpeta de trabajo.
En la siguiente imagen se muestra que en la carpeta en donde están las bases de datos se añadieron tres archvos:
guion01TREs el guión que se construyó para trabajar con la base de datos. En futuras sesiones se hace doble click sobre este nombre para que el RStudio lo abra automáticamente y no es necesario reubicar el RStudio, porque queda configurado correctamente en la carpeta de trabajo..RhistoryEs posible que aparezca como un icono sin nombre, porque el sistema oculta la extensión, que en este caso es ‘.Rhistory’. Este archivo cotiene una bitácora de todos los comando utilizados en la sesión del RStudio..RDataEs posible que tampoco aparezca el nombre, pero si un icono que representa el espacio de trabajo grabado al terminar la sesión. Este archivo NO se debe abrir directamente con el RStudio, porque se trata del entorno. Este archivo lo abre automáticamente el RStudio al iniciar una sesión en el mismo lugar del guión.
Situaciones especiales
Archivo con formato anglosajón (Separados por comas)
Se pueden encontrar archivos que como el siguiente: tiemposReaccion_dif_1.csv, no están separados los campos por comas (,) y no por punto y coma (;) como lo están los formatos latinoamericanos.
En este caso se examina con el block de notas cuál es el tipo de separador, y
de acuerdo a esta situación el código cambia sólo el la función read..
En este caso se utiliza como se muestra a continuación la función read.csv()
# Lectura de los tiempos de reacción.
TR <- read.csv("tiemposReaccion_dif_1.csv")
TR
Archivo con codificación UTF-8 (Codificación más universal)
El formato de windows (latin1) no es universal para la codificación de archivos, por eso es frecuente encontrar archivos como el siguiente, tiemposReaccion_dif_2.csv, que tiene formato UTF-8. Y se identifica porque las tíldes no se leen correctamente.
Para solucionar este inconveniente se procede a modificar el código de la siguiente manera para que la codificación sea la adecuada:
# Lectura de los tiempos de reacción.
TR <- read.csv("tiemposReaccion_dif_2.csv", enc = "UTF-8")
TR
Esta modificación funciona tanto si está en formato latinoamericano, como en
formato anglosajón, es decir que funciona tanto con read.csv2() como
con read.csv().